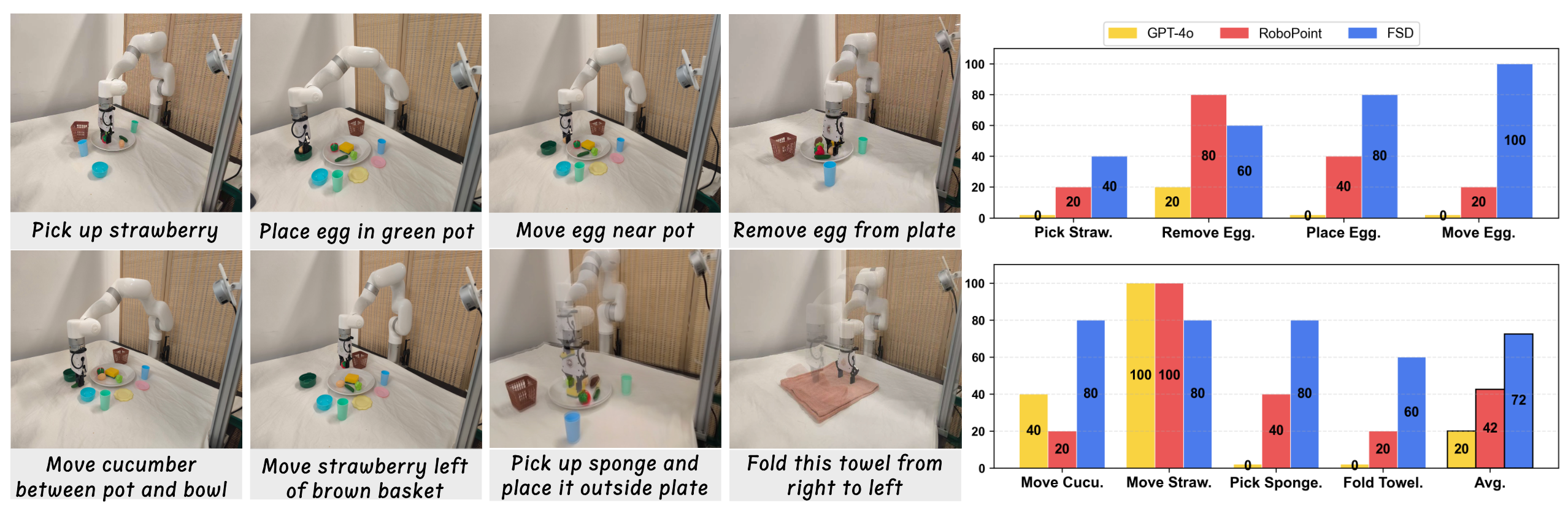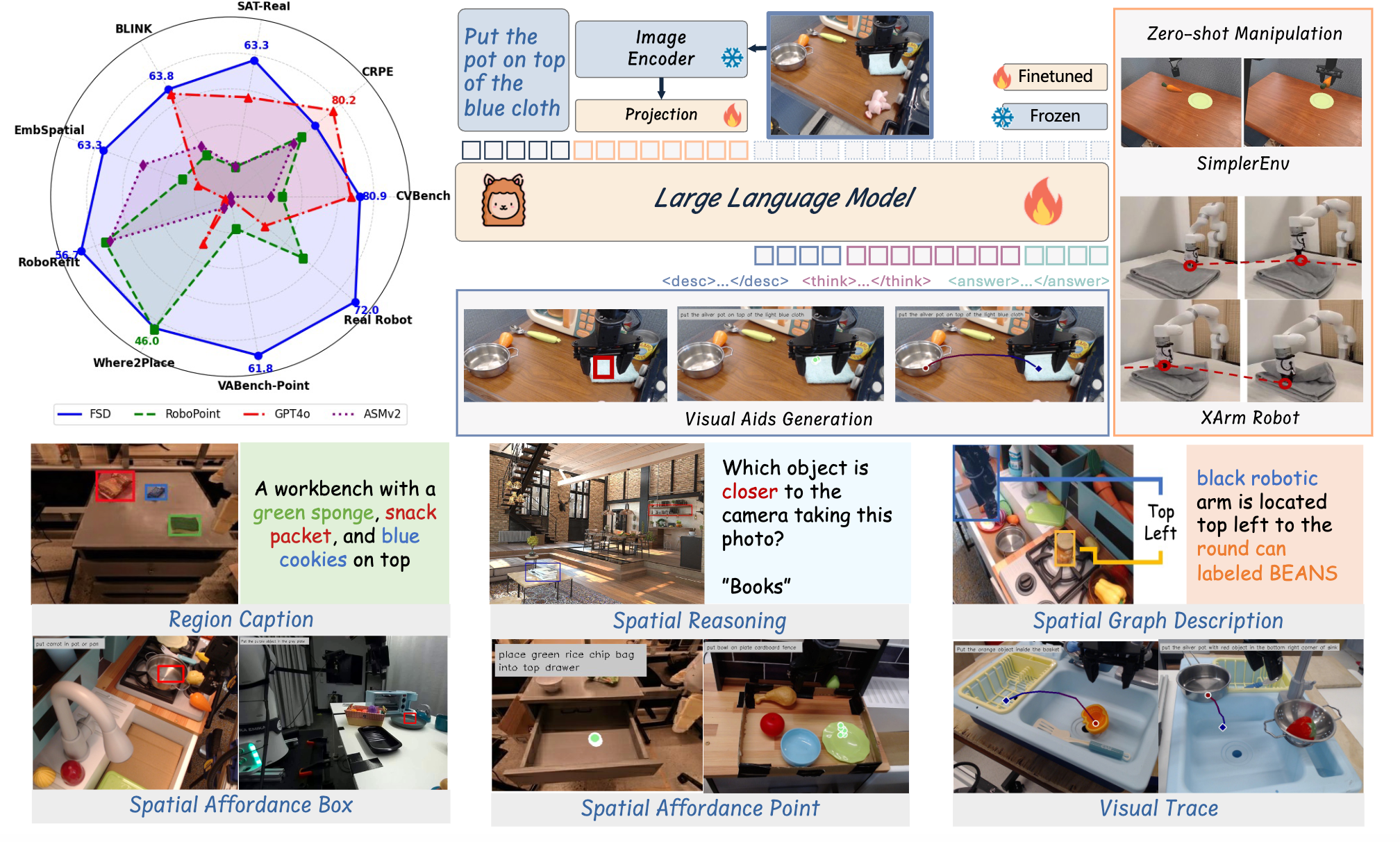
Overview of FSD Framework. FSD unlocks visual aids reasoning and generation through Spatial Relationship-Focused CoT, demonstrating exceptional generalization capabilities that enable zero-shot robot manipulation and achieving remarkable performance across multiple benchmarks.
Method Overview
🎯 Motivation & Challenges
Current Vision-Language-Action (VLA) models fall short of achieving robust zero-shot performance due to two fundamental limitations (Seeing to Doing issue):
- (1) Scarcity: Robotics data remains limited compared to language and vision datasets, preventing similar scaling laws
- (2) Heterogeneity: Significant variation in robot platforms makes end-to-end learning from vision to diverse action outputs challenging
🔬 Our Solution: FSD Pipeline
We present FSD (From Seeing to Doing), a novel pipeline that addresses generalization challenges through spatial relationship reasoning and visual aids generation. Our approach leverages VLMs' visual understanding capabilities, augmented with step-by-step reasoning to extract unified mid-level structural representations independent of robot embodiment.
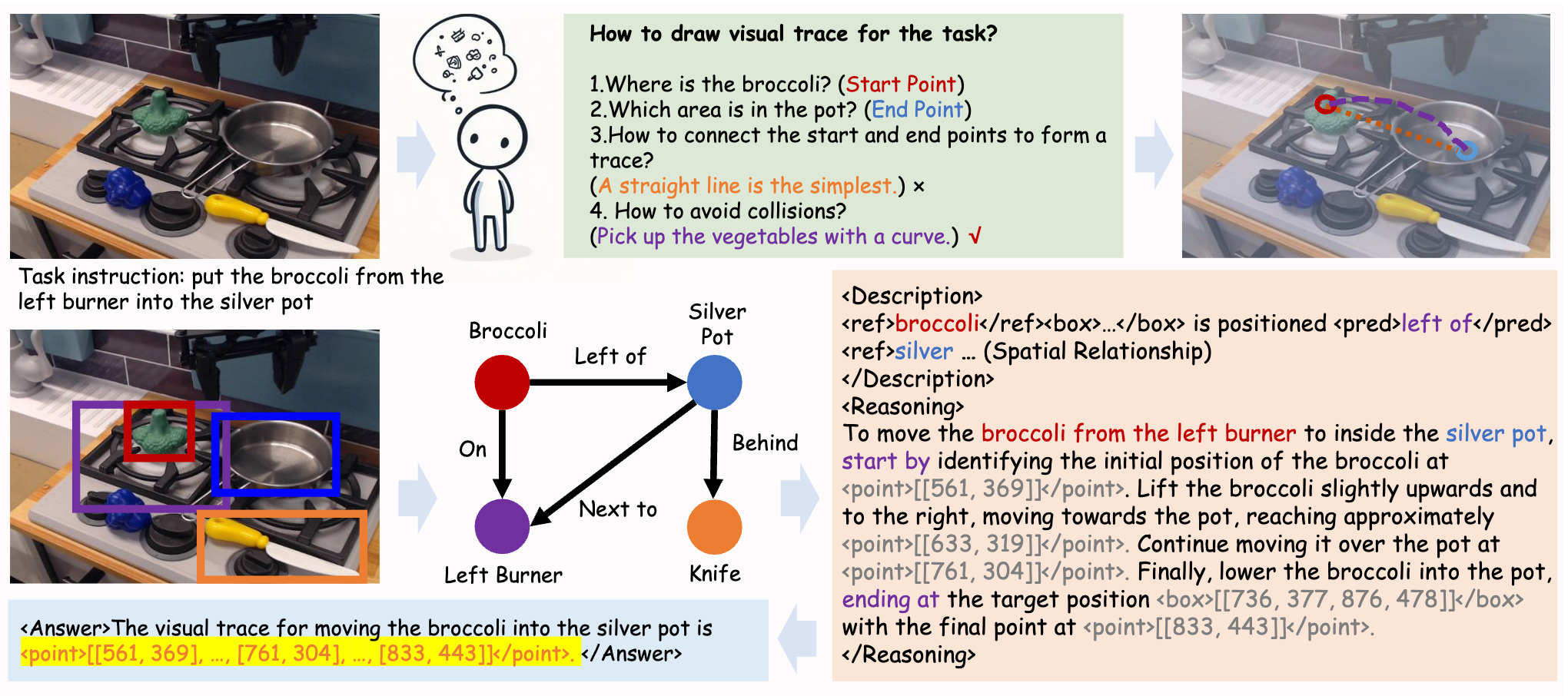
FSD Pipeline Overview. Inspired by the process of human reasoning, FSD uses a
spatial relationship graph as an anchor to derive a visual chain-of-thought reasoning process for visual trace generation.
📍 Visual Aids Representation
Our mid-level representation includes spatial affordance boxes/points and visual traces, each represented as marked coordinates within visual images. These visual aids provide: Expressive spatial information, Compact representation, and Embodiment-independent guidance.
🏗️ Three Core Components
1. Spatial Relationship-Focused Visual Chain-of-Thought (Sr-CoT)
Conducts multi-step reasoning anchored by object coordinates and spatial relationships, treating visual aid generation as a reasoning process. This enables the model to understand complex spatial configurations and generate appropriate visual guides.
2. Weak-to-Strong Data Construction Pipeline
Combines large-scale embodied datasets with common sense data, establishing a weak-to-strong capability enhancement training process. This systematic approach captures fine-grained spatial relationships and manipulation skills across diverse scenarios.
3. Self-Consistency Mechanism
Aligns understanding and generation by binding spatial coordinates with specific visual signals. This ensures robust and consistent decision-making across different scenarios by maintaining coherence between spatial reasoning and visual perception.